Architecture
pg_mooncake brings a modern columnar store based on object storage to Postgres. Table metadata is stored in Postgres for transactional consistency, while all data is stored in object storage or local file system.
We chose Parquet as our file format, with added table metadata from open formats like Iceberg and Delta Lake. This makes Mooncake tables directly queryable by engines like Snowflake, DuckDB, and Spark.
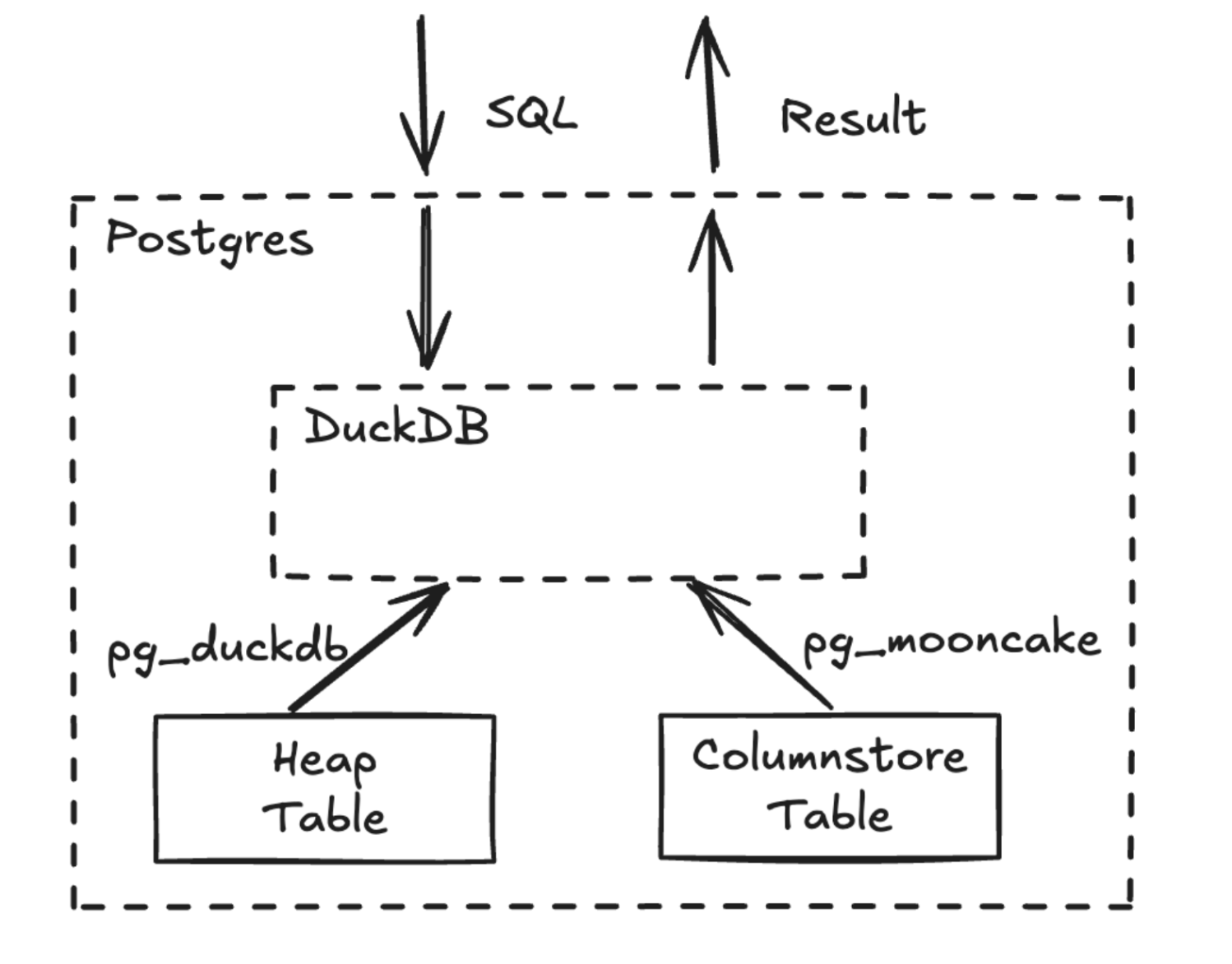
Columnstore tables are exposed as a new Postgres Table Access Method (TAM). Queries involving columnstore tables are routed from Postgres to DuckDB, and the results are streamed back to Postgres via pg_duckdb.
Read Path
Queries involving columnstore tables are routed from Postgres to DuckDB, and the results are streamed back to Postgres via pg_duckdb. Minor query rewrites are applied to bridge the SQL syntax differences.
pg_mooncake is one of the fastest Parquet-based databases (even faster than DuckDB on Parquet). It stores Parquet metadata and column statistics within Postgres and uses these to optimize scans with segment elimination.
Write Path
You can run transactional inserts, updates, and deletes directly on columnstore tables. To support DELETE and UPDATE operations, an implicit row_id column is populated during the TableScan, consisting of (file_id, row_offset) to efficiently identify rows.
Each write operation creates a new Parquet file. Note that pg_mooncake v0.1 is not optimized for small, frequent ingest workloads.
Caching
On writes, data is stored in a cache on disk. This helps us achieve significantly faster queries on hot data. In v0.2, we will be adding read cache functionality, so frequently queried data can be maintained in cache for even faster query performance.